JavaScript 2 and the Open Web
Brendan Eich
20 Nov 2007
Herewith a hacked-up version of my S5 slides, with notes and commentary interpolated at the bottom of each slide.
Dilbert – the Big Time

See how JS is paired with Flash — poor, mundane HTML, CSS, DOM! HTML5 needs a new name.
I described Doug Crockford as “the Yoda of Lambda JavaScript programming” at a mid-2006 talk he invited me to present at Yahoo!, so I thought I would start by riffing on whether the role still fits. So far, so good.
Yoda in Trouble

But three prequels later, the outlook for Yoda is not good. Large, heavy, spinning, flying-saucer-proprietary runtimes are hurtling toward him!
Enough Star Wars — Doug’s too tall for that part (even if it’s only a muppet). Let’s try a taller wizard…
The Bridge of EcmaDoom
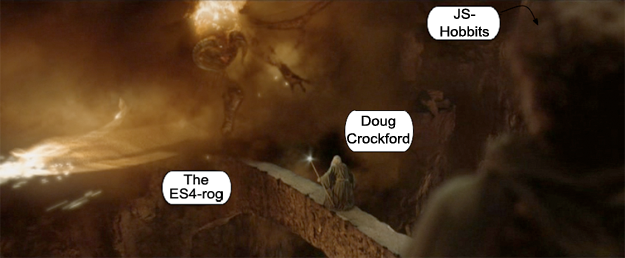
I don’t really believe ES4 is a demon from the ancient world, of course. I’m afraid the JS-Hobbits are in trouble, though. As things stand today, Silverlight with C# or something akin (pushed via Windows Update) will raze the Shire-web, in spite of Gandalf-crock’s teachings.
Mal, Latin for “Bad”

They’ll swing back to the belief that they can make people… better. And I do not hold to that.
– Mal Reynolds, Serenity
I can roleplay too: let’s see, renegade veteran from the losing side of an epic war against an evil empire… yeah, I can relate.
I really do think that JS’s multi-paradigm nature means there is no one-true-subset for all to use (whether they like it or not), and the rest — including evolutionary changes — should be kept out. I reject the idea that instead of making JS better, programmers should somehow be made “better”. The stagnation of JS1, and “little language” idolatries surrounding it (those one-true-way JS subsets), impose a big tax on developers, and drive too many of them away from the web standards and toward WPF, Flex, and the like.
Ok, enough role-playing geek fun — let’s get down to brass tacks: what’s really going on with the ES4 fracas?
- Who decides what is “better”?
- Browser, plugin, and OS vendors?
- Web developers?
- All of the above, ideally
- Without taking too long
- Or making a mess
- Preventing change could spare us from “worse”
- Or help proprietary “change” to take off for the worst
Clearly ES4 will be tough to standardize. Standards often are made by insiders, established players, vendors with something to sell and so something to lose. Web standards bodies organized as pay-to-play consortia thus leave out developers and users, although vendors of course claim to represent everyone fully and fairly.
I’ve worked within such bodies and continue to try to make progress in them, but I’ve come to the conclusion that open standards need radically open standardization processes. They don’t need too many cooks, of course; they need some great chefs who work well together as a small group. Beyond this, open standards need transparency. Transparency helps developers and other categories of “users” see what is going on, give corrective feedback early and often, and if necessary try errant vendors in the court of public opinion.
Given all the challenges, the first order for ES4 work is to finish the reference implementation and spec writing process, taking into account the ongoing feedback. Beyond that, and I said this at the conference, I believe we need several productized implementations well under way, if not all but done, by the time the standard is submitted for approval (late 2008). This will take some hard work in the next ten months.
My hope is to empower developers and users, even if doing so requires sacrifice on the part of the vendors involved.
Inevitable Evolution
- Web browsers are evolving
- They need to, against Silverlight, AIR, and OS stacks
- Browsers (and plugins!) need all three of
- Better Security
- Better APIs for everything (see 1)
- Better programming language support (see 1 and 2)
- No two-legged stools, all three are needed
Some assert that JS1 is fine, browsers just need better APIs. Or (for security), that JS1 with incompatible runtime semantic changes and a few outright feature deletions is fine, but mainly: browsers just need better APIs. Or that Security comes first, and the world should stop until it has been achieved (i.e., utopia is an option). But I contend that JS must improve along with browser APIs and security mechanism and policy, both to serve existing and new uses, and to have a prayer of more robust APIs or significantly better security.
It’s clear from the experiences of Mozilla and security researchers I know that even a posteriori mashups built on a capability system will leak information. So information flow type systems could be explored, but again the research on hybrid techniques that do not require a priori maximum-authority judgments, which do not work on the web (think mashups in the browser without the user having to click “OK” to get rid of a dialog), is not there yet. Mashups are unplanned, emergent. Users click “OK” when they shouldn’t. These are hard, multi-disciplinary research problems.
Where programming languages can help, type systems and mutability controls are necessary, so JS1 or a pure (semantics as well as syntax) subset is not enough.
Evolving Toward “Better”
- Security: hard problem, humans too much in the loop
- APIs: served by WHAT-WG (Apple, Mozilla, Opera)
- Languages: only realistic evolutionary hope is JS2
I am personally committed to working with the Google Caja team, and whoever else will help, to ensure that JS2 (with the right options, and as few as possible) is a good target for Caja. The irony is that when combined with backward compatibility imperatives, this means adding features, not removing them (for example, catchalls).
A note on names: I used JS2 in the title and the slides to conjure with the “JS” and “JavaScript” names, not to show any disrespect to ES/ECMAScript. All the books, the ‘J’ in AJAX (when it’s an acronym), the name of the language dropped most often at the @media Ajax conference, all call the language by the “JavaScript” name. Yeah, it was a marketing scam by Netscape and Sun, and it has a mixed history as a brand, but I think we are stuck with it.
Alternative Languages
- Why not new/other programming languages?
- JS not going away in our lifetimes
- JS code is growing, not being rewritten
- No room for multiple language runtimes in mobile browser
- Apple, Mozilla, Opera attest to this in my hearing
- One multi-language runtime? Eventually, not soon enough
- A patent minefield…
- How many hard problems can we (everyone!) solve at once and quickly?
This slide compresses a lot, but makes some points often missed by fans of other languages. Browsers will always need JS. Browsers cannot all embed the C Python implementation, the C Ruby implementation, etc. etc. — code footprint and cyclic leaks among heaps, or further code bloat trying to super-GC those cycles, plus all the security work entailed by the standard libraries, are deal killers.
The multi-language, one-runtime approach is better, but not perfect: IronPython is not Python, and invariably there is a first-among-equals language (Java on JVMs, C# on the CLR). We are investing in IronMonkey to support IronPython and IronRuby, and in the long run, if everyone makes the right moves, I’m hopeful that this work will pay off in widespread Python and Ruby support alongside JS2. But it will take a long while to come true in a cross-browser way.
Silverlight is not able to provide browser scripting languages in all browsers. Even if IE8 embeds the DLR and CLR, other browsers will not. Note the asymmetry with ScreamingMonkey: it is likely to be needed only by IE, and only IE has a well-known API for adding scripting engines.
Why JS2
- JS1 is too small => complexity tax on library and app authors
- JS1 has too few primitives => hard idiom optimization problem
- JS1 lacks integrity features => better security has to be bolted on
- JS1 is not taught much => Java U. still cranking out programmers
- JS2 aims to cover the whole user curve, “out of the box”
The “too small” and “too few primitives” points remind me of Guy Steele’s famous Growing a Language talk from OOPSLA 1998 (paper). If you haven’t seen this, take the time.
During the panel later the same day, Jeremy Keith confronted me with the conclusion that JS2 was pitched only or mainly at Java heads. I think this slide and the next gave that impression, and a more subtle point was lost.
I hold no brief for Java. JS does not need to look like Java. Classes in JS2 are an integrity device, already latent in the built-in objects of JS1, the DOM, and other browser objects. But I do not believe that most Java U. programmers will ever grok functional JS, and I cite GWT uptake as supporting evidence. This does not mean JS2 panders to Java. It does mean JS2 uses conventional syntax for those magic, built-in “classes” mentioned in the ES1-3 and DOM specs.
In other words, and whatever you call them, something like classes are necessary for integrity properties vital to security in JS2, required for bootstrapping the standard built-in objects, and appropriate to a large cohort of programmers. These independent facts combine to support classes as proposed in JS2.
Normal Distribution
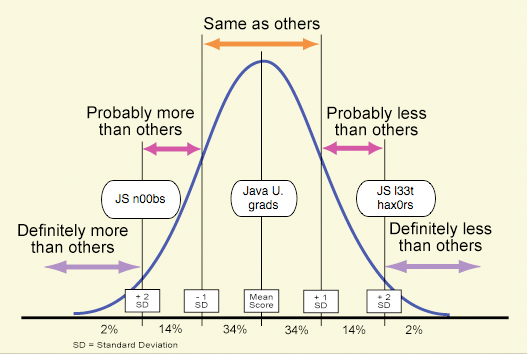
JS1 is used by non-programmers, beginning programmers, “front end designers”. It is copied and pasted, or otherwise concatenatively programmed, with abandon (proof: ES4 has specified toleration of Unicode BOMs in the middle of .js files! How did those get there?). This was a goal, at least in the “pmarca and brendan”@netscape.com vision circa 1995, over against Java applets. We succeeded beyond our wildest nightmares.
Netscape 2 had some very clueful early adopters of JS (Bill Dortch, if you are reading this, leave a comment). Years later, Doug Crockford led more select hackers toward the right end of the distribution, but much of the middle was necessarily bypassed: you can’t reach this cohort without taking over Java U.
What’s more, I observe that the Lambda-JS Jedi order is inherently elitist (I’m not anti-elitist, mind you; natural elites happen in all meritocratic systems). For many current Knights, it must remain so to retain its appeal.
Now, there’s nothing wrong with using closures for (partial) integrity and prototypes for inheritance; I like these tools (I should, I picked them in a hurry in the early days). But really, why should everyone be required to learn the verbose, error-prone, and inherently costly functional-JS-OOP incantations (power constructors, module patterns, etc.), instead of using a few concise, easier to get right, and more efficient new declarative forms that JS2 proposes?
It’s not as if JS2 is renouncing prototypes or closures in favor of “the Java way”. That’s a misinformed or careless misreading. Rather, we aim to level the playing field up, not down. JS2 users should be able to make hardened abstractions without having to write C++ or create Active X objects. And power-constructor and module pattern fans can continue to use their favorite idioms.
Wait a Minute!
Perhaps you object (strenously):
- “I like my JS small, it is not complex with the right kung-fu!”
- “Most runtime is in the DOM, who cares about JS optimizations”
- “Security through smallness, and anyway: fix security first”
- “People are learning, Yoda is teaching them”
JS1 favors closures (behavior with attached state) over objects (state with attached behavior) with both more abstraction (because names can be hidden in closures) and greater integrity (because var bindings are DontDelete). While JS1 is multi-paradigm, going with the grain of the design (closures over objects) wins. In my talk, I acknowledged the good done by Doug and others in teaching people about functional programming in JS.
However, there are limits. JS1 closure efficiency, and outright entrainment hazards that can result in leaks, leave something to be desired (the entrainment hazards led Microsoft to advise JScript hackers to avoid closures!). You could argue that implementations should optimize harder. Arguing is not needed, though — high quality optimizing runtime, which fit on phones, are what’s needed.
Beyond efficiency, using closures for modules and class-like abstractions is verbose and clumsy compared to using new syntax. Dedicating new syntax is scary to some, but required for usability (over against __UGLY__ names), and allowed under script type versioning. In the absence of macros (syntactic abstraction), and so long as macros can be added later and syntactic sugar reimplemented via macros at that time, my view is that we should be generous with syntactic conveniences in JS2.
So JS2 has more syntax (user interface) as well as substance (complementary primitives). This could be a burden on people learning the new language, but I think not a big one. In practice over the next few years, the bulk of the focus in books and classes will be on JS1 and Ajax. A programming language for the web should be a many-storied mountain, and most users will not ascend to the summit.
The main burden of new syntax is on folks writing source-to-source translators, static analyzers, and the like. These more expert few can take the heat so that the many can enjoy better “user interface”.
OK, Granted
- Some truth in these claims, just not enough in my view
- The odds ratios multiply to a pretty small success likelihood
- Meanwhile, Silverlight is charging hard with C# (DLR fan-bait aside)
- Flash and AIR likewise rely on ActionScript 3, not JS1, to compete
- And really, JS1 users who are hitting its limits need relief soon
To respond to the contrarian arguments in the previous slide:
- Whoever prefers a subset is free to continue using it on JS2 implementations. If your pointy-haired boss imposes class-obsessed B&D programming on you, get a new job.
- DOM profiles show high dynamic dispatch, argument/result conversion, and other costs imposed by untyped JS1 in current implementations. Better implementations and JS2 usage can help.
- Security is best defined as end-to-end properties that must be engineered continuously according to economic trade-offs as the system evolves. Utopia is not an option.
- Some people are learning, but many others are not, and vendors sell C# and AS3 against JS1 for good reason.
As Neil Mix wryly observed in a post to the es4-discuss list:
When I hear concerns that ES4 will “break the web,” I can’t help but think of how many times I’ve heard that the web is already broken! The risks of not adopting ES4 surely must factor into this calculus, too.
Why Not Evolve?
- We’re not proto-humans from 2001: A Space Odyssey
- Making space ships out of bones
- Or modules out of lambdas
- We’re highly-evolved tool users, with opposable thumbs — we can:
- Make better use of an existing tool (JS1)
- Improve the tool itself (JS2)
- Why not do both?
At the very least, don’t put all eggs in the “make people better” basket.
But… But…
You may still object:
- “JS should remain small no matter what!”
- “Classes suck, I hate my pointy-haired Java boss”
- “Aren’t you rejecting your own elegant (yet messy) creation?”
- “Who replaced you with a pod-person? We don’t even know you any longer!”
I get all kinds of fan-mail :-/.
What I Seek
- To make JS (not people)… better
- Better for its present and near-future uses on the web
- Especially for building Ajax libraries and applications
- JS programs are increasing in size and complexity
- They face increasing workload — lots of objects, runtime
- JS users deserve improvements since ES3 (eight years ago)
The argument that stagnation on the web fostered Ajax and Web 2.0 is false. Only when XMLHttpRequest was cloned into other browsers, and especially as Firefox launched and took market share back from IE, did we see the sea-change toward web apps that rely on intensive browser JS and asynchronous communication with the server.
In Particular
- JS users deserve an optional type system
- Instead of tedious (often skipped) error checking
- So APIs can prove facts about their arguments
- Without requiring all calling code to be typed
- (… at first, or ever!)
- They deserve integrity guarantees such as
const
- They deserve real namespaces, packages, compilation units
- They deserve some overdue “bug fixes” to the ES3 standard
- They deserve generous syntactic sugar on top
Like Mal Reynolds, I really do believe these things — not that I’m ready to die for my beliefs (“‘Course, that ain’t exactly plan A”).
The Deeper Answer
Why JS2 as a major evolutionary jump matters:
- So browsers and plugins lose their “native-code innovation” lock
- Downloaded JS2 code can patch around old native code bugs
- Or reimplement a whole buggy subsystem, at near-native (or better!) speed
- No more waiting for IE (or Firefox, or Safari, or Opera)
- Distributed extensibility, web developers win
There won’t be a single browser release after which all power shifts to web developers writing in JS2. The process is more gradual, and it’s easy to forget how far we’ve come already. We’re well along the way toward disrupting the desktop OSes. Yet JS2 on optimizing VMs will liberate developers in ways that JS1 and plugins cannot.
Believe It
- Yes, this was the Java dream that died in 1995, or 1997
- This time for sure (Tamarin may be the most widely deployed VM ever)
- It’s coming true with JS — if only it can evolve enough in time
I lived through the Java dream. Netscape was building an optimizing JIT-compiling runtime in 1996 and 1997, while Sun acquired Anamorphic and built HotSpot. The layoffs at the end of 1997 brought all the Netscape Java work crashing to a halt, and caused the “Javagator” rendering engine team to reinvent their code in C++ as Gecko (originally, “Raptor”).
In spite of all the hype and folly, the dream could have come true given both enough time and better alignment (including open source development) between Sun and Netscape. A lot more time — Java was slow back then, besides being poorly integrated into browsers.
There are many ironies in all of this. Two I enjoy often:
- Flash filled the vacuum left by the decline of Java in the browser, and now provides a vector for JS2 on Tamarin.
- Microsoft dumped Java, depriving Outlook Web Access of an asynchronous I/O class, wherefore
XMLHttpRequest.
Non-Issues
- JS1 performance on synthetic pure-JS (no DOM) benchmarks
- Trace-based JITing accelerates JS1 at least an order of magnitude
- Work from Michael Franz‘s group at UC Irvine (Mozilla supported)
- No
int type annotations required
- Preliminary results based on Tamarin-to-Java bytecode translation, with a custom tracing JIT targeting the JVM (whew!), next…
If you take only one point away from this talk (I said), it should be that type annotations are not required for much-improved pure JS performance.
Tracing JIT Benchmarks

This chart shows results, normalized using SpiderMonkey performance at unity (so taller is faster), for the JavaGrande benchmark ported to JS (untyped JS except where noted: “Tamarin with Type Annotations”). The “Trace-Tree JIT” blue bars show results for a clever translation of Tamarin bytecode into Java bytecode (with runtime type helpers) fed into a tracing JIT implemented in Java(!). Amazingly, this approach competes with Rhino and Tamarin, even Tamarin run on typed-JS versions of the benchmarks.
The Crypt benchmark could not be run using the trace-based JIT at the time this chart was generated.
Tracing JIT Benchmarks (2)

More good results, especially given the preliminary nature of the research. With an x86 back-end instead of the Java back-end used for these benchmarks, and further tuning work, performance should go up significantly. Even at this early stage, Series, SOR, and SparseMatMult all show the tracing JIT working with untyped JS beating Tamarin on typed-JS versions of these benchmarks.
Non-Issues (2)
- Making JS2 look like any other language
- Stuart, yesterday: fans already fake JS1 to resemble Ruby, Python, …
- But: JS2 learns from other languages
- AS3: nominal types, namespaces, packages
- Python: iterators and generators, catch-alls
- Dylan, Cecil: generic methods
- Only those who don’t learn history are doomed to repeat it
- Problems will be shaken out in ES4 “beta”
- No rubber-stamped standards! (cough OOXML)
In response to an informal recap of my presentation the other day, Rob Sayre mentioned Peter Norvig‘s presentation on design patterns in dynamic programming. This caused me to flash back to the bad old days of 1998, when certain “Raptor” architects would wave the Gamma book and make dubious assertions about one-true-way design patterns in C++.
Norvig’s slides show what was lost by the swerve toward static, obsessively classical OOP in C++ and Java, away from dynamic languages with first-class functions, first-class types, generic methods, and other facilities that make “patterns” invisible or unnecessary. JS2 aims to restore to practical programmers much of what was lost then.
Integrity in JS2
- Object, Array, etc., globals can be replaced in JS1
- JSON CSRF hazards pointed out by Joe Walker
- ECMA spec says this matters, or not, half the time
- JS2 makes the standard class bindings immutable
- Objects are mutable, extensible
- Even with privileged/private members via closures
- Too easy to forge instance of special type
- JS2 has
class exactly to solve this problem
- JS2 lets users make fixtures, fixed (“don’t delete”) properties
- JS1 user-defined properties can be replaced/hijacked
The Romans called wheat integrale, referring to the potent and incorruptible completness of the kernel. Integrity as a security property is not far removed from this sense of completeness and soundness. JS1 simply lacks crucial tools for integrity, and JS2 proposes to add them.
The following slides (I’ve coalesced multiple slides where possible) show the evolution of a webmail library from JS1 to JS2, via gradual typing, in order to increase integrity and simplify code, avoiding repetitious, error-prone hand-coded latent type checking. The transport code is omitted, but you can see JSON APIs being used for transfer encoding and decoding.
Evolutionary Programming
Version 1 of a webmail client, in almost pure JS1
function send(msg) {
validateMessage(msg);
msg.id = sendToServer(JSON.encode(msg));
database[msg.id] = msg;
}
function fetch() {
handleMessage(-1); // -1 means "get new mail"
}
function get(n) {
if (uint(n) !== n) // JS1: n>>>0 === n
throw new TypeError;
if (n in database)
return database[n];
return handleMessage(n);
}
var database = [];
function handleMessage(n) {
let msg = JSON.decode(fetchFromServer(n));
if (typeof msg != "object")
throw new TypeError;
if (msg.result == "no data")
return null;
validateMessage(msg);
return database[msg.id] = msg;
}
function validateMessage(msg) {
function isAddress(a)
typeof a == "object" && a != null &&
typeof a.at == "object" && msg != null &&
typeof a.at[0] == "string" && typeof a.at[1] == "string" &&
typeof a.name == "string";
if (!(typeof msg == "object" && msg != null &&
typeof msg.id == "number" && uint(msg.id) === msg.id &&
typeof msg.to == "object" && msg != null &&
msg.to instanceof Array && msg.to.every(isAddress) &&
isAddress(msg.from) && typeof msg.subject == "string" &&
typeof msg.body == "string"))
throw new TypeError;
}
It’s rare to see anything in real-world JS like the detailed checking done by validateMessage. It’s just too tedious, and the language “fails soft” enough (usually), that programmers tend to skip such chores — sometimes to their great regret.
Evolution, Second Stage
Version 2: Structural types for validation.
type Addr = { at: [string, string], name: string };
type Msg = {
to: [Addr], from: Addr, subject: string, body: string, id: uint
};
function send(msg: like Msg) {
msg.id = sendToServer(JSON.encode(msg));
database[msg.id] = msg;
}
function fetch()
handleMessage(-1);
function get(n: uint) {
if (n in database)
return database[n];
return handleMessage(n);
}
function handleMessage(n) {
let msg = JSON.decode(fetchFromServer(n));
if (msg is like { result: string } && msg.result == "no data")
return null;
if (msg is like Msg)
return database[msg.id] = msg;
throw new TypeError;
}
Important points:
- Structural types are like JSON, but with types instead of values
- The
like type prefix makes a “shape test” spot-check
- Note how
fetch is now an expression closure
- No more
validateMessage! Structural types ftw! 🙂
Evolution, Third Stage
Version 3a: Integrity through structural type fixtures (other functions are unchanged since Version 2)
type MsgNoId = {
to: [Addr], from: Addr, subject: string, body: string
};
function send(msg: like MsgNoId) {
msg.id = sendToServer(JSON.encode(msg));
database[msg.id] = copyMessage(msg);
}
function handleMessage(n) {
let msg = JSON.decode(fetchFromServer(n));
if (msg is like { result: string } && msg.result == "no data")
return null;
if (msg is like Msg)
return database[id] = copyMessage(msg);
throw new TypeError;
}
function copyMessage(msg) {
function newAddr({ at: [user, host], name })
new Addr([user, host]: [string, string], name);
let { to, from, subject, body, id } = msg;
return new Msg(to.map(newAddr), newAddr(from), subject, body, id);
}
This stage copes with a confused or malicious client of the webmail API, who could mutate a reference to a message to violate the validity constraints encoded in stage 1’s validateMessage.
The MsgNoId type allows the library client to omit a dummy id, since send initializes that property for the client.
Note the righteous use of parameter and let destructuring in copyMessage.
Alternative Third Stage
Version 3b (other functions are unchanged since Version 3a)
function send(msg: like MsgNoId) {
msg.id = sendToServer(JSON.encode(msg))
database[msg.id] = msg wrap Msg
}
function handleMessage(n) {
let msg = JSON.decode(fetchFromServer(n))
if (msg is like { result: string } && msg.result == "no data")
return null
return database[msg.id] = msg wrap Msg
}
wrap is both an annotated type prefix and a binary operator in JS2. It makes a wrapper for an untyped object that enforces a structural type constraint on every read and write, in a deep sense. So instead of copying to provide integrity through isolation, this alternative third stage shares the underlying message object with the library client, but checks all accesses made from within the webmail library.
Observations on Evolution
- At no point so far did clients have to use types
- Code shrank by half from stage 1 to 3a, more to 3b
- First stage just used a tiny bit of JS2 (
uint)
- Second stage added structural types and
is like tests
- Sanity-checking the “shape” of API arguments
- But trusting the client not to mutate behind the library’s back!
- Third stage copied into structural type instances with fixtures — integrity against confused/malicious client
- Alternative third stage used
wrap instead
Notice the lack of classes so far.
Observations on Evolution (2)
- A “modularization” stage would use
package or namespace
- If copying or wrapping too costly, drop
like from formal params, and either:
- Change client to pass structural type instances
- Or use nominal types (
class, interface) throughout
- Either way, client changes required at this point
- Use optional strict mode for verification before deployment
- (Many thanks to Lars Thomas Hansen for the example code)
UPDATE: A revised and extended version of this evolutionary arc is now available as a tutorial at ecmascript.org, with compelling side-by-side comparisons of successive stages.
Conclusions
- JS2 focuses on programming in the large and code migration:
- Evolutionary programming with structural types
- Gradual typing from
like to wrap or fixed types
- Rapid prototypes start out untyped, just like today
- We believe most web JS can remain untyped, with good performance
- Library APIs and implementations can buy integrity and efficiency by the yard
- Higher integrity with efficiency may induce “islands” of typed code (e.g., real-time games)
The “typed APIs with untyped code” pattern is particularly winning in our experience building the self-hosted built-ins in the ES4 reference implementation.
What Else Is New?
- ScreamingMonkey lives! It runs a self-hosted ES4 compiler that generates bytecode from the compiler’s own source
- Much optimization work remains to be done
- But the C# chess demo from MIX07, ported to ES4, runs now
- ScreamingMonkey chess demo is ~15x faster than the JScript version (per fresh e-mail today from Mark Hammond)
- Demos of two other new APIs, the <video> tag and 3D <canvas>, follow…
During this slide, I shot screaming slingshot flying monkeys (complete with little black masks and capes) into the audience. I’m sorry I could bring only a handful on this trip!
Video Tag Demo
- Implements the WHAT-WG <video> tag proposal
- Opera and now Apple have implemented too
- page-defined DHTML playback controls
- Uses Ogg Theora and Vorbis for video and audio
- Embeds <video> in SVG <foreignObject> for transforms
- Developed by Chris Double
Chris provides source code, Firefox 3 alpha builds, and Ogg video/audio files.
Canvas3D Demo
- Alternative OpenGL-ES rendering context for <canvas>
- Embeds OpenGL’s shader language in <script>, read via DOM
- Example KMZ (Google Earth) viewer
- Developed by Vladimir Vukicevic
Now available as a Firefox 3 addon!
Finis